This chapter provides information on the Inference Engine plugins that enable inference of deep learning models on the supported VPU devices:
- Intel® Neural Compute Stick 2 powered by the Intel® Movidius™ Myriad™ X — Supported by the MYRIAD Plugin
- Intel® Vision Accelerator Design with Intel® Movidius™ VPUs — Supported by the HDDL Plugin
NOTE: With OpenVINO™ 2020.4 release, Intel® Movidius™ Neural Compute Stick powered by the Intel® Movidius™ Myriad™ 2 is no longer supported.
Known Layers Limitations
'ScaleShift'layer is supported for zero value of'broadcast'attribute only.'CTCGreedyDecoder'layer works with'ctc_merge_repeated'attribute equal 1.'DetectionOutput'layer works with zero values of'interpolate_orientation'and'num_orient_classes'parameters only.'MVN'layer uses fixed value for'eps'parameters (1e-9).'Normalize'layer uses fixed value for'eps'parameters (1e-9) and is supported for zero value of'across_spatial'only.'Pad'layer works only with 4D tensors.
Optimizations
VPU plugins support layer fusion and decomposition.
Layer Fusion
Fusing Rules
Certain layers can be merged into Convolution, ReLU, and Eltwise layers according to the patterns below:
- Convolution
- Convolution + ReLU → Convolution
- Convolution + Clamp → Convolution
- Convolution + LeakyReLU → Convolution
- Convolution (3x3, stride=1, padding=1) + Pooling (2x2, stride=2, padding=0) → Convolution
- Pooling + ReLU → Pooling
- FullyConnected + ReLU → FullyConnected
- Eltwise
- Eltwise + ReLU → Eltwise
- Eltwise + LeakyReLU → Eltwise
- Eltwise + Clamp → Eltwise
Joining Rules
NOTE: Application of these rules depends on tensor sizes and resources available.
Layers can be joined when the two conditions below are met:
- Layers are located on topologically independent branches.
- Layers can be executed simultaneously on the same hardware units.
Decomposition Rules
Convolution and Pooling layers are tiled resulting in the following pattern:
- A Split layer that splits tensors into tiles
- A set of tiles, optionally with service layers like Copy
- Depending on a tiling scheme, a Concatenation or Sum layer that joins all resulting tensors into one and restores the full blob that contains the result of a tiled operation
Names of tiled layers contain the
@soc=M/Npart, whereMis the tile number andNis the number of tiles: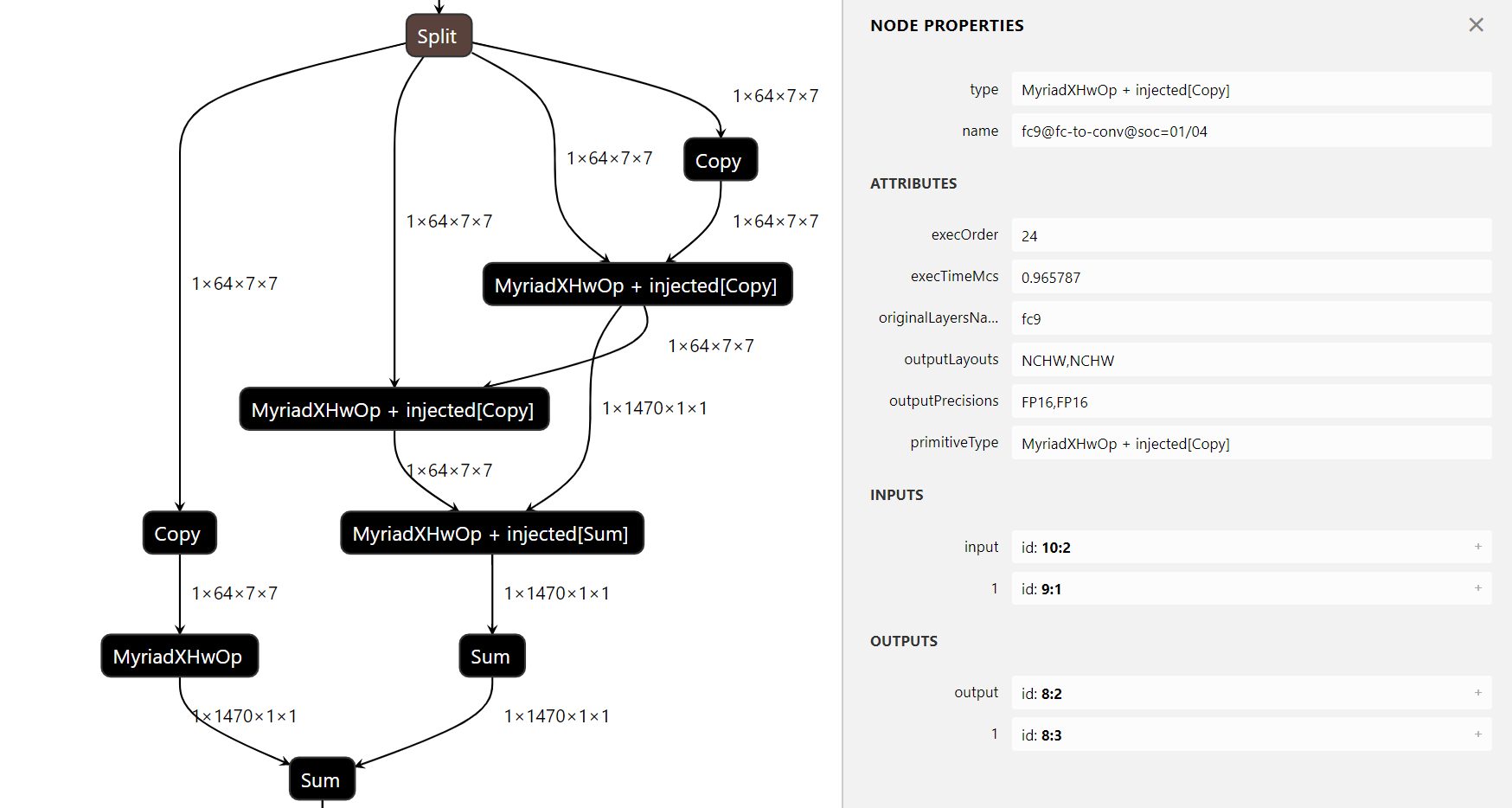
NOTE: Nominal layers, such as Shrink and Expand, are not executed.
NOTE: VPU plugins can add extra layers like Copy.
VPU Common Configuration Parameters
The VPU plugins supports the configuration parameters listed below. The parameters are passed as std::map<std::string, std::string> on InferenceEngine::Core::LoadNetwork or InferenceEngine::Core::SetConfig. When specifying key values as raw strings (that is, when using Python API), omit the KEY_ prefix.
| Parameter Name | Parameter Values | Default | Description |
|---|---|---|---|
KEY_VPU_HW_STAGES_OPTIMIZATION | YES/NO | YES | Turn on HW stages usage Applicable for Intel Movidius Myriad X and Intel Vision Accelerator Design devices only. |
KEY_VPU_COMPUTE_LAYOUT | VPU_AUTO, VPU_NCHW, VPU_NHWC | VPU_AUTO | Specify internal input and output layouts for network layers. |
KEY_VPU_PRINT_RECEIVE_TENSOR_TIME | YES/NO | NO | Add device-side time spent waiting for input to PerformanceCounts. See Data Transfer Pipelining section for details. |
KEY_VPU_IGNORE_IR_STATISTIC | YES/NO | NO | VPU plugin could use statistic present in IR in order to try to improve calculations precision. If you don't want statistic to be used enable this option. |
KEY_VPU_CUSTOM_LAYERS | path to XML file | empty string | This option allows to pass XML file with custom layers binding. If layer is present in such file, it would be used during inference even if the layer is natively supported. |
Data Transfer Pipelining
MYRIAD plugin tries to pipeline data transfer to/from device with computations. While one infer request is executed the data for next infer request can be uploaded to device in parallel. Same applicable for result downloading.
KEY_VPU_PRINT_RECEIVE_TENSOR_TIME configuration parameter can be used to check the efficiency of current pipelining. The new record in performance counters will show the time that device spent waiting for input before starting the inference. In perfect pipeline this time should be near to zero, which means that the data was already transferred when new inference started.
Troubleshooting
Get the following message when running inference with the VPU plugin: "[VPU] Cannot convert layer <layer_name> due to unsupported layer type <layer_type>"
This means that your topology has a layer that is unsupported by your target VPU plugin. To resolve this issue, you can implement the custom layer for the target device using the Inference Engine Extensibility mechanism. Or, to quickly get a working prototype, you can use the heterogeneous scenario with the default fallback policy (see the HETERO Plugin section). Use the HETERO plugin with a fallback device that supports this layer, for example, CPU: HETERO:MYRIAD,CPU. For a list of VPU supported layers, see the Supported Layers section of the Supported Devices topic.