Introducing CPU Plugin
The CPU plugin was developed in order to provide opportunity for high performance scoring of neural networks on CPU, using the Intel® Math Kernel Library for Deep Neural Networks (Intel® MKL-DNN).
Currently, the CPU plugin uses Intel® Threading Building Blocks (Intel® TBB) in order to parallelize calculations. Please refer to the Optimization Guide for associated performance considerations.
The set of supported layers can be expanded with the extensibility library. To add a new layer in this library, you can use the extensibility mechanism.
Supported Platforms
OpenVINO™ toolkit is officially supported and validated on the following platforms:
| Host | OS (64-bit) |
|---|---|
| Development | Ubuntu* 16.04/CentOS* 7.4/MS Windows* 10 |
| Target | Ubuntu* 16.04/CentOS* 7.4/MS Windows* 10 |
The CPU Plugin supports inference on Intel® Xeon® with Intel® AVX2 and AVX512, Intel® Core™ Processors with Intel® AVX2, Intel Atom® Processors with Intel® SSE.
You can use -pc the flag for samples if you would like to know which configuration is used by some layer. This flag shows execution statistics that you can use to get information about layer name, execution status, layer type, execution time and the type of the execution primitive.
Internal CPU Plugin Optimizations
CPU plugin supports several graph optimization algorithms:
-
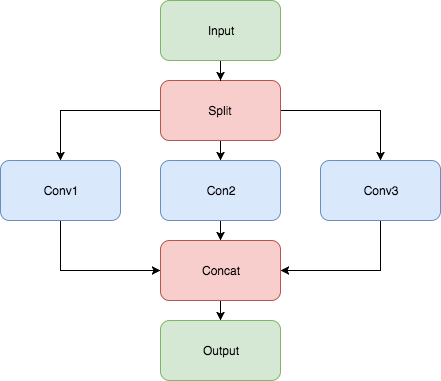
Merging of group convolutions. It means that if a topology contains the following pipeline: CPU plugin will merge it into one Convolution with the group parameter (Convolutions should have the same parameters).
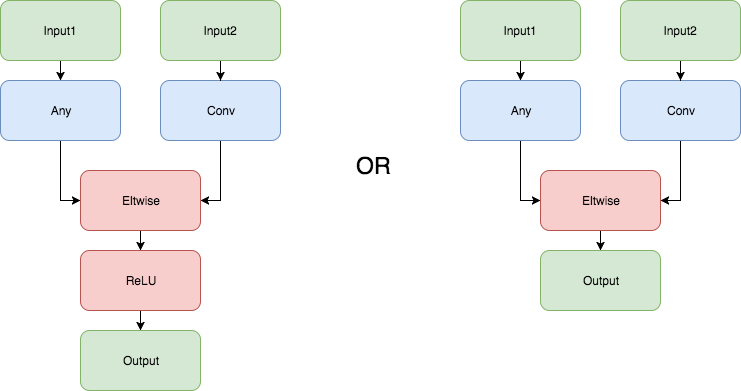
- Fusing of Convolution with ReLU or ELU. CPU plugin is fusing all Convolution with ReLU or ELU layers if these layers are located after the Convolution layer.
- Removing power layer. CPU plugin removes Power layer from topology if it has the following parameters: power = 1, scale = 1, offset = 0.
-
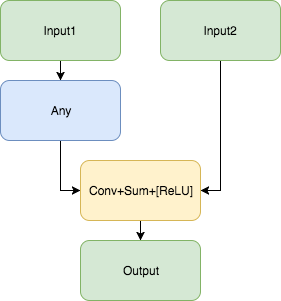
Fusing Convolution + Sum or Convolution + Sum + ReLU. In order to improve performance, CPU plugin fuses the next structure: This fuse allows you to upgrade the graph to the following structure:
Supported Configuration Parameters
The plugin supports the configuration parameters listed below. All parameters must be set with the InferenceEngine::IInferencePlugin::LoadNetwork() method. Refer to the OpenVINO samples for usage examples: Benchmark App.
These are general options, also supported by other plugins:
| Parameter name | Parameter values | Default | Description |
|---|---|---|---|
| KEY_EXCLUSIVE_ASYNC_REQUESTS | YES/NO | NO | Forces async requests (also from different executable networks) to execute serially. This prevents potential oversubscription |
| KEY_PERF_COUNT | YES/NO | NO | Enables gathering performance counters |
CPU-specific settings:
| Parameter name | Parameter values | Default | Description |
|---|---|---|---|
| KEY_CPU_THREADS_NUM | positive integer values | 0 | Specifies number of threads that CPU plugin should use for inference. Zero (default) means using all (logical) cores |
| KEY_CPU_BIND_THREAD | YES/NO | YES | Binds inference worker threads to CPU cores. The binding is usually performance friendly, especially in server scenarios. The option also limits number of OpenMP* or Intel(R) TBB threads to the number of hardware cores. |
| KEY_CPU_THROUGHPUT_STREAMS | KEY_CPU_THROUGHPUT_NUMA, KEY_CPU_THROUGHPUT_AUTO, or positive integer values | 1 | Specifies number of CPU "execution" streams for the throughput mode. Upper bound for a number of inference requests that can be executed simulteneously. All available CPU cores are evenly distributed between the streams. The default value is 1, which implies latency-oriented behaviour with all available cores processing requests one by one. KEY_CPU_THROUGHPUT_NUMA creates as many streams as needed to accomodate NUMA and avoid associated penalties. KEY_CPU_THROUGHPUT_AUTO creates bare minimum of streams to improve the performance; this is the most portable option if you don't know how many cores your target machine has (and what would be the optimal number of streams). Notice that your application should provie enough parallel slack (e.g. run many inference requests) to leverage the throughput mode. A positive integer value creates the requested number of streams. |