Model Optimizer is a cross-platform command-line tool that facilitates the transition between the training and deployment environment, performs static model analysis, and adjusts deep learning models for optimal execution on end-point target devices.
Model Optimizer process assumes you have a network model trained using a supported deep learning framework. The scheme below illustrates the typical workflow for deploying a trained deep learning model:
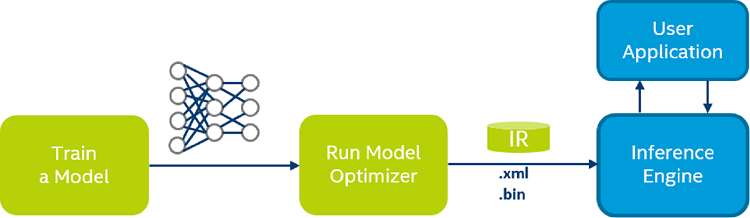
Model Optimizer produces an Intermediate Representation (IR) of the network, which can be read, loaded, and inferred with the Inference Engine. The Inference Engine API offers a unified API across a number of supported Intel® platforms. The Intermediate Representation is a pair of files describing the model:
-
.xml- Describes the network topology -
.bin- Contains the weights and biases binary data.
What's New in the Model Optimizer in this Release?
- TensorFlow*
- Improved workflow for converting TensorFlow* Objection Detection API models conversion:
- For this type of topologies, the Model Optimizer generates input layer dimensions based on two parameters: the
--input_shapeCLI parameter and image resizer type that is defined in thepipeline.configfile. - Model Optimizer generates a number of
PiorBoxClusterednodes instead of theConstnode with priorboxes so that you can reshape SSD models in the Inference Engine. - Non-square input image sizes are supported.
- Added support for the RFCN topology.
- For this type of topologies, the Model Optimizer generates input layer dimensions based on two parameters: the
- Added support for more TensorFlow* operations. The full list of supported operations is defined in the Supported Framework Layers.
- Added the command line parameter
--tensorflow_custom_layer_librariesto load shared libraries with custom TensorFlow* operations to reuse shape inference function.
- Improved workflow for converting TensorFlow* Objection Detection API models conversion:
- MXNet*
- Added support for more MXNet* operations. The full list of supported operations is defined in the Supported Framework Layers.
- ONNX*
- Added support for more ONNX* operations. The full list of supported operations is defined in the Supported Framework Layers.
- Common
- The default IR version is increased from 2 to 3. Since the IR version 3 introduces new layers and attributes, previous versions of the Inference Engine may not be able to infer them. The IR with version 2 can be generated using the
--generate_deprecated_IR_V2command line parameter. - Duplicated weights are removed from the IR, so several layers can share the same blob.
- Meta information is added to the IR with information about command line parameters used and the Model Optimizer version.
- The default IR version is increased from 2 to 3. Since the IR version 3 introduces new layers and attributes, previous versions of the Inference Engine may not be able to infer them. The IR with version 2 can be generated using the
Notice that certain topology-specific layers (like DetectionOutput used in the SSD*) are now shipped in a source code, which assumes the extensions library is compiled/loaded. The extensions are also required for the pre-trained models inference.
Table of Content
- Introduction to Intel® Deep Learning Deployment Toolkit
-
Preparing and Optimizing your Trained Model with Model Optimizer
- Configuring Model Optimizer
-
Converting a Model to Intermediate Representation (IR)
- Converting a Model Using General Conversion Parameters
- Converting Your Caffe* Model
-
Converting Your TensorFlow* Model
- Converting YOLO from DarkNet to Tensorflow and then to IR
- Converting FaceNet from TensorFlow
- Converting DeepSpeech from TensorFlow
- Converting Language Model on One Billion Word Benchmark from TensorFlow
- Converting Neural Collaborative Filtering Model from TensorFlow*
- Converting TensorFlow* Object Detection API Models
- Converting TensorFlow*-Slim Image Classification Model Library Models
- Converting CRNN Model from TensorFlow*
- Converting Your MXNet* Model
- Converting Your Kaldi* Model
- Converting Your ONNX* Model
- Model Optimizations Techniques
- Cutting parts of the model
- Sub-graph Replacement in Model Optimizer
- Supported Framework Layers
- IR Notation Reference
- Custom Layers in Model Optimizer
- Model Optimizer Frequently Asked Questions
- Known Issues
Typical Next Step: Introduction to Intel® Deep Learning Deployment Toolkit